
外出時に移動時間が長くなると、ポッドキャストや録音していたラジオ番組を聴いています。
先日は「さいとう・たかを」のインタビュー放送がおもしろく、再度聴いてみたいと思ったものの、同じ番組を冒頭から聴き直すのも時間がかかります。
また、内容によっては、文字にして紹介したいということもあるかもしれません。
Whisperで文字起こしをしてみました。
Whisperとは
Whisperとは、音声を自動で文字起こしをしてくれる音声認識AIモデルです。
日本語にも対応しています。
早速、「Whisperを使って文字起こし」と思ったものの、具体的にどのようにしていいのか見当がつきません。
いつくかの記事の中でわかりやすかったのが、agusblog さんのブログ
「【Whisper】ローカルでWhisperを実行し文字起こしする方法について解説」
手順が丁寧に解説されています。
この方法に従えば、録音データから文字起こしをすることが可能なはずです。
少なくとも私の場合は、うまくいきました。
大変助かりました。ありがとうございます。
記事にあるように、VS Code、Python、Git でいけるので、それほど難易度は高くなさそうです。
エラーの修正
今回文字起こしをしたのは、NHKの「カルチャーラジオ NHKラジオアーカイブス 声でつづる昭和人物史」。
「さいとう・たかを」の1回目です。
「声でつづる昭和人物史」は、激動の昭和という時代に生きた人々を紹介する番組。
NHKのインタビュー音源で構成されていて、昭和という時代、そして、その人物を知ることのできる内容となっています。
今回は、Dドライブの中にフォルダーをつくり、「test」とリネームしたm4aファイルを文字起こししてもらいます。
VS Codeに先ほどのサイトのコードをそのまま貼り付け。
ファイル名を変更するなどして実行します。
エラー その1
ファイル名を変更しPythonを書き直して実行したところ、VS Codeのターミナルには、つぎのような警告とエラーが表示されてしまいました。
D:\download\whisper\whisper_test.py:3: SyntaxWarning: invalid escape sequence ‘\d’
fileName = “D:\download\whisper\content\test.m4a”FileNotFoundError: [WinError 2] 指定されたファイルが見つかりません。
PS C:\download\whisper>
です。
誤解のないようにお断りしておくと、先ほどのサイトの説明が間違っているわけではありません。
私が修正した内容に誤りがあったためです。
このようなプログラムの修正は、ChatGPTが得意とするところ。
これまでだと、説明サイトを検索して自分で修正する必要がありました。
プログラム言語は世界共通なので、場合によっては英語のサイトなども参照して解決をしていたところです。
それがChatGPTだと、エラー内容を質問するだけで修正をしてくれます。
今回もエラー内容を書いたところ、次の回答がありました。
例えば最初の警告については、
SyntaxWarning: invalid escape sequence ‘\d’
この警告は、パスの “D:\download\whisper\content\test.m4a” に含まれる \d などがエスケープシーケンスとして誤解されているために発生しています。修正方法
パスを生の文字列(raw string)として扱うか、バックスラッシュを \ にすると解決できます。
また、エラーについても、
FileNotFoundError: [WinError 2] 指定されたファイルが見つかりません。
これは whisper.load_audio(f”content/{fileName}”) の部分で、fileName にすでにフルパスが指定されているため、誤ったパスになってしまっている可能性が高いです。修正方法
ファイル名を直接 whisper.load_audio(fileName) に渡す
と回答があります。
さらに、修正プログラムを書いてくれます。
エラー その2
ChatGPTに修正してもらったプログラムを貼り付け実行したところ再度のエラー
次のような表示となります。
raceback (most recent call last):
File “D:\download\whisper\whisper_test.py”, line 12, in
audio = whisper.load_audio(fileName)
File “C:\Users\xxxxx\AppData\Roaming\Python\Python313\site-packages\whisper\audio.py”, line 58, in load_audio
out = run(cmd, capture_output=True, check=True).stdout
これもどこが悪いのか質問します。
数秒で返ってきた答えが
このエラーの原因として考えられるのは、FFmpegがインストールされていない、またはパスが通っていないことです。whisper.load_audio(fileName) は内部的に FFmpeg を使用して音声を読み込むため、FFmpegが正しく動作していないと FileNotFoundError: [WinError 2] が発生します。
とのこと。
参照したサイトを再確認すると、FFmpegのインストールについても書いてありました。
これも私の見落としです。
無事実行
VS Codeのターミナルから実行してみます。
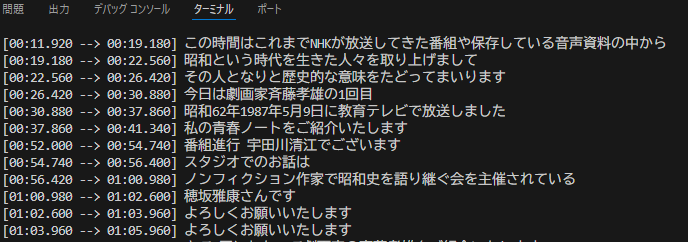
このように経過時間と文字が対応して表示されます。
- 「さいとう・たかを」が「斉藤孝雄」
- 「保阪正康」が「穂坂雅康」
などと人名の漢字変換は不正確ですが、ほかの部分はほぼ正しく文字起こしができています。
また、テキストファイルに格納されたのは、こちら。

改行などがされずに、読みづらいところがあります。
こちらは、Chatに渡して句読点を入れてもらうことで解決できます。
本日のまとめ
Whisperを使った文字起こし。
冒頭にも書きました agusblog さんの
【Whisper】ローカルでWhisperを実行し文字起こしする方法について解説

ステップバイステップでわかりやすく、手順どおりに進めていけば文字起こしができるようになります。
とても参考になりました。ありがとうございます。
私の理解不足や読み落としは、ChatGPTに直してもらうことで解決。
最近は、
- 参考となるサイトの内容をもとに、自分なりにプログラムを作成
- 思いどおりに動かない箇所・エラー箇所はChatGPTに質問し、修正してもらう
という使い方をするようになってきました。
短時間で意図するプログラムを作りやすくなったと感じます。

